We recently finished our responses for the INSPIRE Shakespeare Blog Award. They helped us think about the impact maintaining this blog, with all of our dedicated readers, has had on our research. We thought it would be interesting to share our answers with you all as well, especially since these are joint answers with input from both of us. Thank you all of accompanying us on this amazing journey, and we hope you enjoyed reading about our research!
What have you learned by blogging about your research?
Blogging our research helped us thoroughly explore our topic while maintaining a strict schedule. We wanted to put out a post about once every week, so we mapped out our expected update schedule, allowing us to also schedule which sections of our paper we hoped to complete. These deadlines allowed us to comfortably finish our work, without fear of falling behind. Additionally, we learned to collaborate as we divided blog posts and ideas between each other. By dividing up the blog posts, we were able to ensure both of us had a mutual understanding of the ideas discussed, and if there were any misunderstandings, or ideas we may have missed. Maintaining this blog also helped us think about how to present our research as well, especially in an informal, casual manner. This was especially useful when we approached potential mentors with our ideas. Finally, blogging helped us explore ideas as we could evaluate what was important to put in our paper, considering feedback we received from readers. What we were able to explore thoroughly on the blog were topics we knew we could also delve deeper into in our paper, allowing us to publish a more in-depth analysis paper.
Why do you think you deserve to win the INSPIRE Blog Award?
Blogging to both of us was a new experience, especially since neither of us have ever maintained a blog before or are in journalism. We used the blog uniquely as a tool to grow as writers and learn how to present our work. We also used the blog as a networking tool. Not only did we reach out to other potential competitors (who hopefully were INSPIREd by our topic), we also presented our blog to fellow peers, our mentor, and others who gave insightful feedback. When creating the schedule of blog posts, we made sure that our blog holisitcally reflected our project, from milestone updates (https://hackingthemalware.blogspot.com/2018/01/placehold-11018.html), to simple techniques to avoid social engineering that we found while researching (https://hackingthemalware.blogspot.com/2017/12/happy-holidays-online-shopping-safety.html). Furthermore, our blog somewhat represented an official record to the public of our project, an important artifact to maintain in the midst of rapid technological advancement, especially with AI. We would love to receive this award as a bittersweet finale to our project, but most importantly, for documenting our findings to impact science, technology, and society.
How has your research experience shaped your career or academic aspirations?
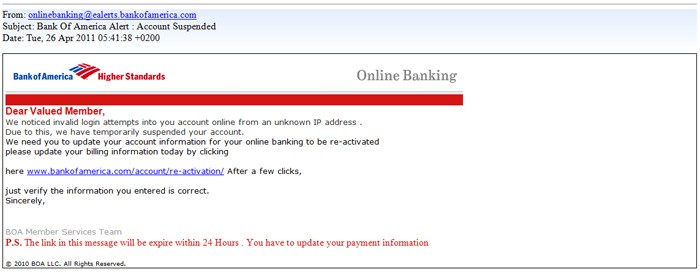
A large part of the reason we decided to try humanities research was to compare the experience to STEM research, which we are familiar with ( https://hackingthemalware.blogspot.com/2017/11/introduction-113017.html). One of our surprises was realizing that our philosophy research was as time-consuming and intensive, if not more, as STEM research. Through this research, we also found many bridges between humanities and STEM, and focused on how these two fields are interconnected. For example, in our research, we learned that the network security industry primarily focuses on creating firewalls. However, 95% of malware attacks are based off of social engineering, which attacks the user themselves, not their system. Hence, we found it much more important to protect consumers from a social angle rather than a technical viewpoint, even designing a browser-based phishing identifier using deep learning to accomplish this.
Humanities research with such strong connections to cryptography and machine learning has certainly opened a new door for us in thinking about computer science. We both intend to pursue CS, and our interest is stronger than ever, especially with the implications we have learned with this research. However, we aspire to continue exploring the humanities side of CS and technology as well, as our experience has shown us that looking at problems like network security from a different angle (predominance of viruses vs. social engineering) can show what would have a greater impact on society and what is more important to create.
Once more, thank you all for supporting us! We hope you enjoyed this insight, as well as our blog.
-James and Sohini
What have you learned by blogging about your research?
Blogging our research helped us thoroughly explore our topic while maintaining a strict schedule. We wanted to put out a post about once every week, so we mapped out our expected update schedule, allowing us to also schedule which sections of our paper we hoped to complete. These deadlines allowed us to comfortably finish our work, without fear of falling behind. Additionally, we learned to collaborate as we divided blog posts and ideas between each other. By dividing up the blog posts, we were able to ensure both of us had a mutual understanding of the ideas discussed, and if there were any misunderstandings, or ideas we may have missed. Maintaining this blog also helped us think about how to present our research as well, especially in an informal, casual manner. This was especially useful when we approached potential mentors with our ideas. Finally, blogging helped us explore ideas as we could evaluate what was important to put in our paper, considering feedback we received from readers. What we were able to explore thoroughly on the blog were topics we knew we could also delve deeper into in our paper, allowing us to publish a more in-depth analysis paper.
Why do you think you deserve to win the INSPIRE Blog Award?
Blogging to both of us was a new experience, especially since neither of us have ever maintained a blog before or are in journalism. We used the blog uniquely as a tool to grow as writers and learn how to present our work. We also used the blog as a networking tool. Not only did we reach out to other potential competitors (who hopefully were INSPIREd by our topic), we also presented our blog to fellow peers, our mentor, and others who gave insightful feedback. When creating the schedule of blog posts, we made sure that our blog holisitcally reflected our project, from milestone updates (https://hackingthemalware.blogspot.com/2018/01/placehold-11018.html), to simple techniques to avoid social engineering that we found while researching (https://hackingthemalware.blogspot.com/2017/12/happy-holidays-online-shopping-safety.html). Furthermore, our blog somewhat represented an official record to the public of our project, an important artifact to maintain in the midst of rapid technological advancement, especially with AI. We would love to receive this award as a bittersweet finale to our project, but most importantly, for documenting our findings to impact science, technology, and society.
How has your research experience shaped your career or academic aspirations?
A large part of the reason we decided to try humanities research was to compare the experience to STEM research, which we are familiar with ( https://hackingthemalware.blogspot.com/2017/11/introduction-113017.html). One of our surprises was realizing that our philosophy research was as time-consuming and intensive, if not more, as STEM research. Through this research, we also found many bridges between humanities and STEM, and focused on how these two fields are interconnected. For example, in our research, we learned that the network security industry primarily focuses on creating firewalls. However, 95% of malware attacks are based off of social engineering, which attacks the user themselves, not their system. Hence, we found it much more important to protect consumers from a social angle rather than a technical viewpoint, even designing a browser-based phishing identifier using deep learning to accomplish this.
Humanities research with such strong connections to cryptography and machine learning has certainly opened a new door for us in thinking about computer science. We both intend to pursue CS, and our interest is stronger than ever, especially with the implications we have learned with this research. However, we aspire to continue exploring the humanities side of CS and technology as well, as our experience has shown us that looking at problems like network security from a different angle (predominance of viruses vs. social engineering) can show what would have a greater impact on society and what is more important to create.
Once more, thank you all for supporting us! We hope you enjoyed this insight, as well as our blog.
-James and Sohini